今天看了看网站的访问日志发现有一个 User Agent 是 Mozilla/5.0 (compatible; SemrushBot/7~bl; +http://www.semrush.com/bot.html) 的蜘蛛一直非常频繁地爬取网站,而且看着二十多 Mb 的日志就知道爬取网站已经有好一段时间了。

网站日志
根据这个蜘蛛爬取的网页来看,应该是将以前爬取过的网页的一些参数进行随机组合再进行访问爬取,所以爬取的链接都是一大串的而且基本上返回的都是 404。再加上每隔几秒钟就爬取一次导致日志里面的正常访问记录基本上淹没在几万行的垃圾蜘蛛记录中。
一开始觉得既然是蜘蛛就应该遵守 robots.txt 吧,就想着给 robots.txt 加上规则就好了:
User-agent: SemrushBot
Disallow: /
结果网上一查才知道这东西似乎并不遵守 robots.txt 😅(在官方页面中声称蜘蛛严格遵守 robots.txt,但是从网上的反馈来看并非如此),而且不只是这个 SemrushBot 很多营销蜘蛛都不遵守 robots.txt。没办法只能用 Nginx 来屏蔽掉了。在宝塔的 Nginx 免费防火墙里面的全局配置中点击 User-Agent 过滤 的规则,加上下面这个正则表达式(从网上汇总而来的,没想到有这么多,顺便也将一些没用的 UA 也加上去了,使用前请看看有没有需要用的 UA):
(nmap|NMAP|HTTrack|sqlmap|Java|zgrab|Go-http-client|CensysInspect|leiki|webmeup|Python|python|curllCurl|wget|Wget|toutiao|Barkrowler|AhrefsBot|a Palo Alto|ltx71|censys|DotBot|MauiBot|MegaIndex.ru|BLEXBot|ZoominfoBot|ExtLinksBot|hubspot|FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|Bytespider|Ezooms|JikeSpider|SemrushBot)
之后等几秒钟就可以看到拦截的数据了。

拦截数据
后面看着一直飙升的拦截数字想到只需要发起请求了无论是返回 404 还是 444,都会消耗服务器资源,这样几秒十几秒一次的一直请求也不是长久之计。再翻了翻这些蜘蛛的 IP 都是国外的节点,而我的网站国外线路也解析到了 Cloudflare,那就刚好可以让 Cloudflare 从中间帮我挡着,不至于让其访问到网站。

蜘蛛 IP
Cloudflare 进入对应的域名控制台后,进入安全性的 WAF 项,点击添加规则。在表达式预览中加入下面的表达式(同样的使用前请检查有没有屏蔽了需要用的 UA):
CodeBlock Loading...
然后选择操作选择阻止后保存即可。
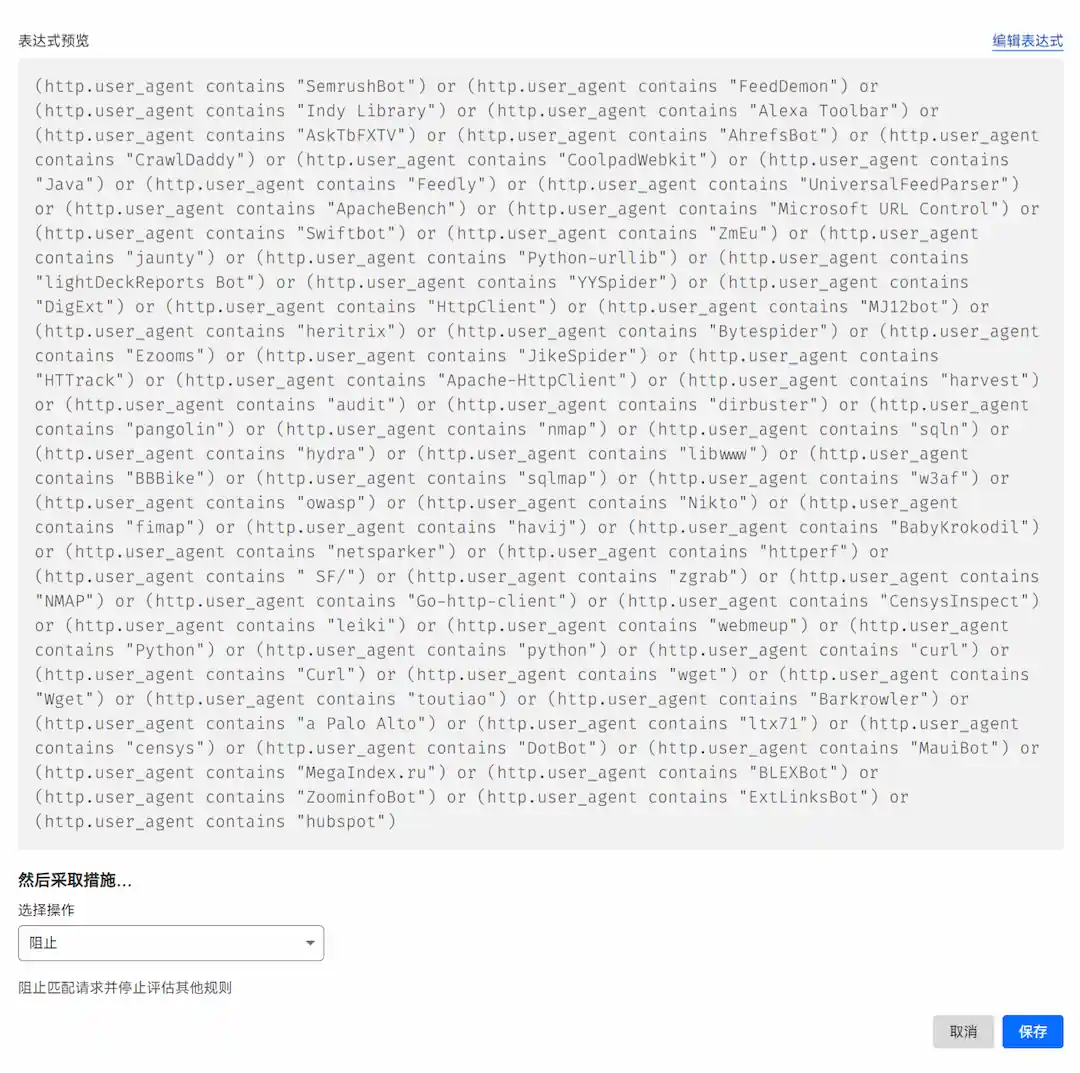
Cloudflare 自定义规则
到此,如果宝塔的 Nginx 免费防火墙的风险拦截数字不再增加。而 Cloudflare 的防火墙规则拦截数疯狂增加的时候就证明已经从 Cloudflare 成功拦截到这些垃圾蜘蛛的访问了。
睡醒更新
一觉睡醒了就已经屏蔽了两千多次了,这东西真的是锲而不舍啊😅。

Cloudflare 自定义规则